Speaking as an employed, white, hetero, cis-gendered, married, educated, male, millenial, trash archer, washed point guard, pseudo-anarcho-communist, wannabe lifter, and #rstats enthusiast, Python is trash.1
See what I did there? Before making a statement, I offered what is either (A) disclaimer, (B) self-justification, or (C) privileged boast. There are subtle differences between them. If a disclaimer or self-justification, the implication is that–given my identity “lens”–I can’t really help why I feel this way, and my interlocutor should listen charitably. If a privileged boast, I’m asserting that my identity/perspective is worthwhile or perhaps even superior to whomever or whatever I’m engaging. This mode of communication is ubiquitious, but is especially hilarious on Twitter. People really tweet some wild things after ‘speaking as…’.
But who are these people and what are they saying? Thanks to the trusty rtweet package, we can extract a random sample of ‘identity tweets’:
library(rtweet)
library(stringr)
library(tidyverse)
tweets <- rtweet::search_tweets(q = '"speaking as a"',
n = 18000,
include_rts = FALSE)Next, I define a series of regex to isolate the self-identifications. Tweets are messy, typo-ridden, and sometimes nonsensical, but this hacky approach extracted most of the tweeter’s identities. The code could absolutely be improved with more time and interest.
r1 <- "[Ss]peaking,? as a [^,.-;*!?]*"
r2 <- "[Ss]peaking as a \\w+ \\w+"
r3 <- "[Ss]peaking as a \\w+"
clean_tweets <- tweets %>%
mutate(identity1 = str_extract(text, regex(r1, ignore_case = TRUE))) %>%
mutate(identity2 = case_when(
is.na(identity1) ~ str_extract(text, regex(r2, ignore_case = TRUE)),
TRUE ~ identity1
)) %>%
mutate(identity3 = case_when(
is.na(identity2) ~ str_extract(text, regex(r3, ignore_case = TRUE)),
TRUE ~ identity2
)) %>%
select(text, tweet_identity = identity3, contains("reply")) %>%
filter(!grepl("a $", tweet_identity),
!is.na(tweet_identity)) %>%
mutate(tweet_identity = str_to_lower(tweet_identity)) %>%
mutate(tweet_identity = str_remove_all(tweet_identity, "speaking,? as a")) %>%
mutate(tweet_identity = str_trim(tweet_identity)) %>%
rowwise() %>%
mutate(tweet_identity = str_split(tweet_identity, "\\)")[[1]][1]) %>%
mutate(tweet_identity = str_split(tweet_identity, " [Ii] ")[[1]][1]) %>%
mutate(tweet_identity = str_split(tweet_identity, " who ")[[1]][1]) %>%
ungroup()To the plots! What are the most common identities within this sample?
clean_tweets %>%
count(tweet_identity, sort = TRUE) %>%
head(30) %>%
ggplot(aes(reorder(tweet_identity, n), n)) +
geom_col(fill = "steelblue") +
labs(x = NULL,
y = "Tweets",
title = '"Speaking as a..."',
subtitle = "Tweets Expressing Identity",
caption = "Data extracted with rwteet on March 30, 2019") +
coord_flip() +
theme_light()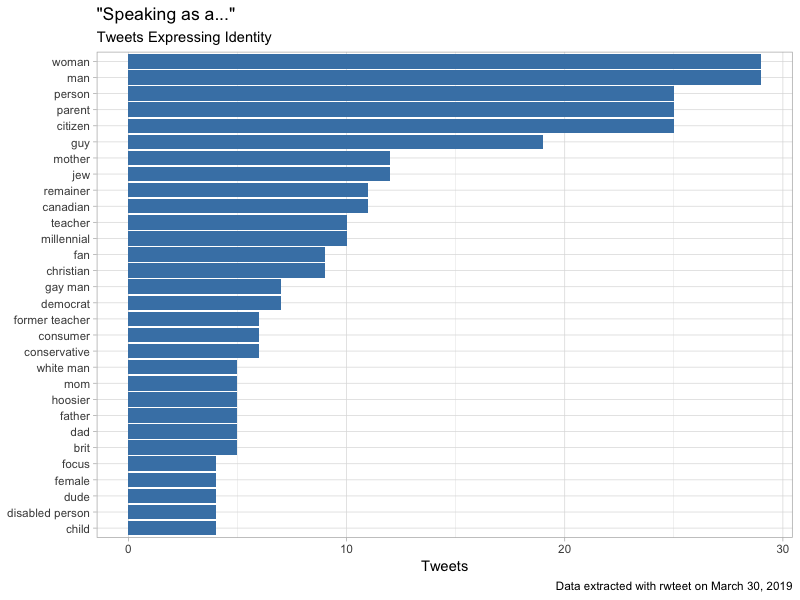
Some observations:
- I checked the ‘citizen’ tweets and although I had excluded RTs from the search, the same text was getting tweeted by what looks like multiple bot accounts.
- These tweets are almost exclusively about politics or sports. You know, the two things people get the most crazy about. LOTS of Brexit talk.
- There are roughly even distributions of ‘liberal’ identities (e.g. democrat, socialist, liberal) and ‘conservative’ identities (‘republican’, ‘libertarian’, ‘conservative’)
- There are roughly even distrbutions of the binary gendered, ‘male’ (guy, dude, man, father, dad) and ‘female’ (girl, woman, mother, mom)
- There is no overlap in hashtags used.
- The vast majority of these tweets are replies to other tweets.
The final observation merits further analysis. There’s something especially ‘Twitter’ and very ‘online’ about responding to someone else with ‘Speaking as a…’. Check the distribution:
clean_tweets %>%
count(is_reply = !is.na(reply_to_status_id)) %>%
ggplot(aes(is_reply, n, fill = is_reply)) +
geom_col(show.legend = FALSE) +
theme_light() +
labs(x = "Reply Tweet?",
y = "Tweets",
title = "Someone said something? Well, as a...",
subtitle = "Tweets expressing identity by replies") +
scale_fill_manual(values = c("forestgreen", "firebrick"))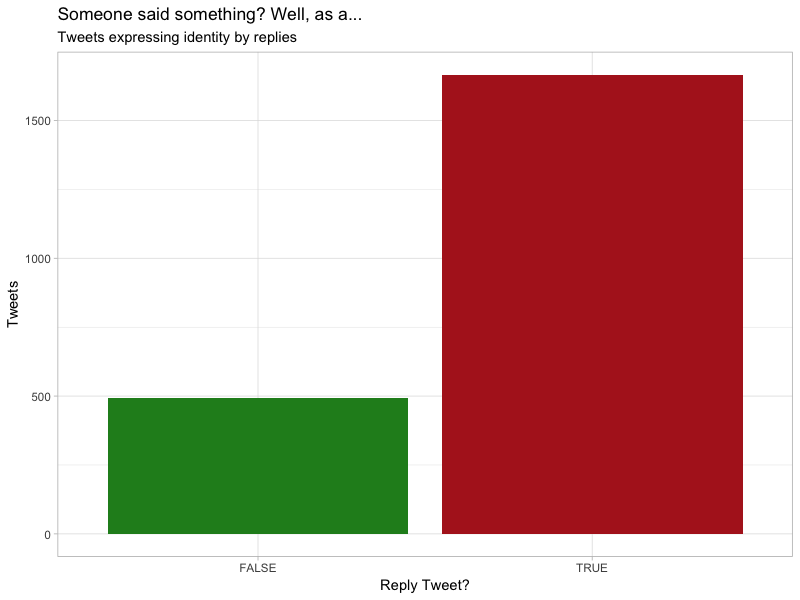
People just love tweeting opinions couched by their identities. And just for fun, here is a sampling of my favorite Twitter identities.
Speaking as a…
- non-white liberal and the son of god
- burglar myself
- magical unicorn
- woman who is tired of dusting and cleaning all my life
- person who weeps uncontrollably at even a passing remembrance of “baby mine”
- broke ass college-going bitch
- classically trained actor
- guy who has sacrificed every aspect of his life in exchange for the well being of two kids
- transhumanist
- quasi-professional in both museum curation and lotr
- responsible mature person
- male mammal
- millennial with some measure of success career-wise
- wife who would throw down if my husband developed a fan-girl harem
- proud hummusexual
- former asst crown attorney who articled in the top ontag’s office
- former “cussing saint” that still slips up with a freaking and oh my god
- descendant of my ancestor who fought in the revolution and was in charge of stealing weapons from the british
- person whose own last name is one letter away from mcgee and who had sex many times
Lol.
Bear with me now for some foolishness. What follows is a rehearsal of the excellent ‘Two Proportions’ section of Modern Dive: Statistical Inference via Data Science. Here is our silly hypothesis test.
Null Hypothesis: There is no association between ‘male tweets’ (e.g. the tweeter self-identified as male) and the liklihood that the tweet was a response to another tweet.
Alternative Hypothesis: A self-identifying ‘male tweet’ is more likely to be a response to another tweet.
Alternative Alternative Hypothesis: MANSPLAINING IS REAL
First, let’s glance at a frequency table:
male_tweets <- clean_tweets %>%
mutate(is_male = ifelse(grepl("guy|dude", tweet_identity) |
grepl(" man", tweet_identity) |
grepl(" male", tweet_identity), "male", "not male"),
is_reply = ifelse(is.na(reply_to_status_id), "not reply", "reply"))
janitor::tabyl(male_tweets, is_male, is_reply)
is_male not reply reply
male 19 113
not male 474 1553Is the difference statistically significant? There is a difference in proportions, but is our sample too small? To find out, let’s do some randomization testing and generate a distribution of differences in proportions:
obs_stat <- male_tweets %>%
specify(is_reply ~ is_male, success = "reply") %>%
calculate(stat = "diff in props", order = c("male", "not male"))
set.seed(2019)
null_distn_two_props <- male_tweets %>%
specify(is_reply ~ is_male, success = "reply") %>%
hypothesize(null = "independence") %>%
generate(reps = 10000) %>%
calculate(stat = "diff in props", order = c("male", "not male"))
null_distn_two_props %>%
visualize() +
shade_p_value(obs_stat, direction = "both")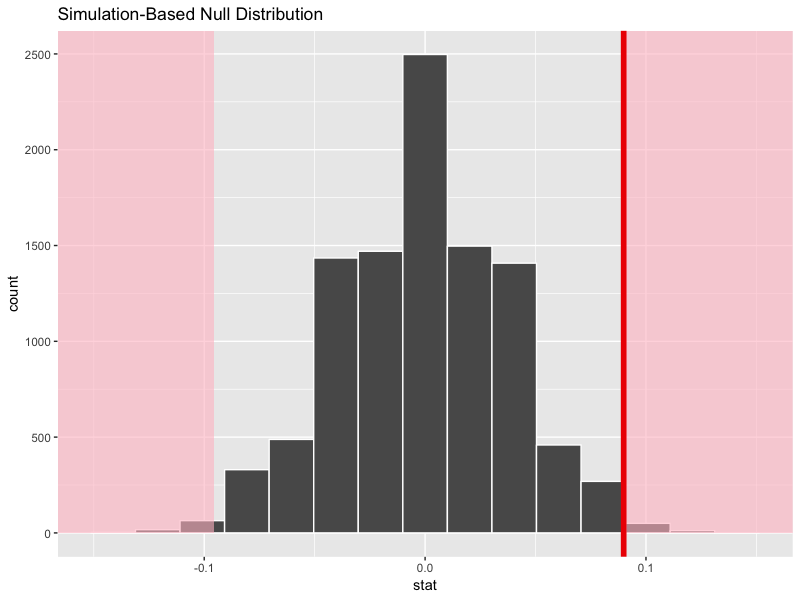
Hmmm, did we just statistically prove the existence of mansplaining???
null_distn_two_props %>%
get_pvalue(obs_stat = obs_stat, direction = "two_sided")
# A tibble: 1 x 1
p_value
<dbl>
1 0.022Less than 0.05! Null hypothesis rejected! Sorry men–speaking as a man, we have a tendency to reply to other people’s tweets.
-
Joking. ↩