The {dbplyr} package is one of the greatest abstractions of all time. The purpose of this blog, however, is to further extend the abstractions into your IDE, scripts, and package code. The benefits are slight but worthwhile: a little less typing, a little less rote memory, and a little increased...
[Read More]
Automating Rmarkdown Reporting
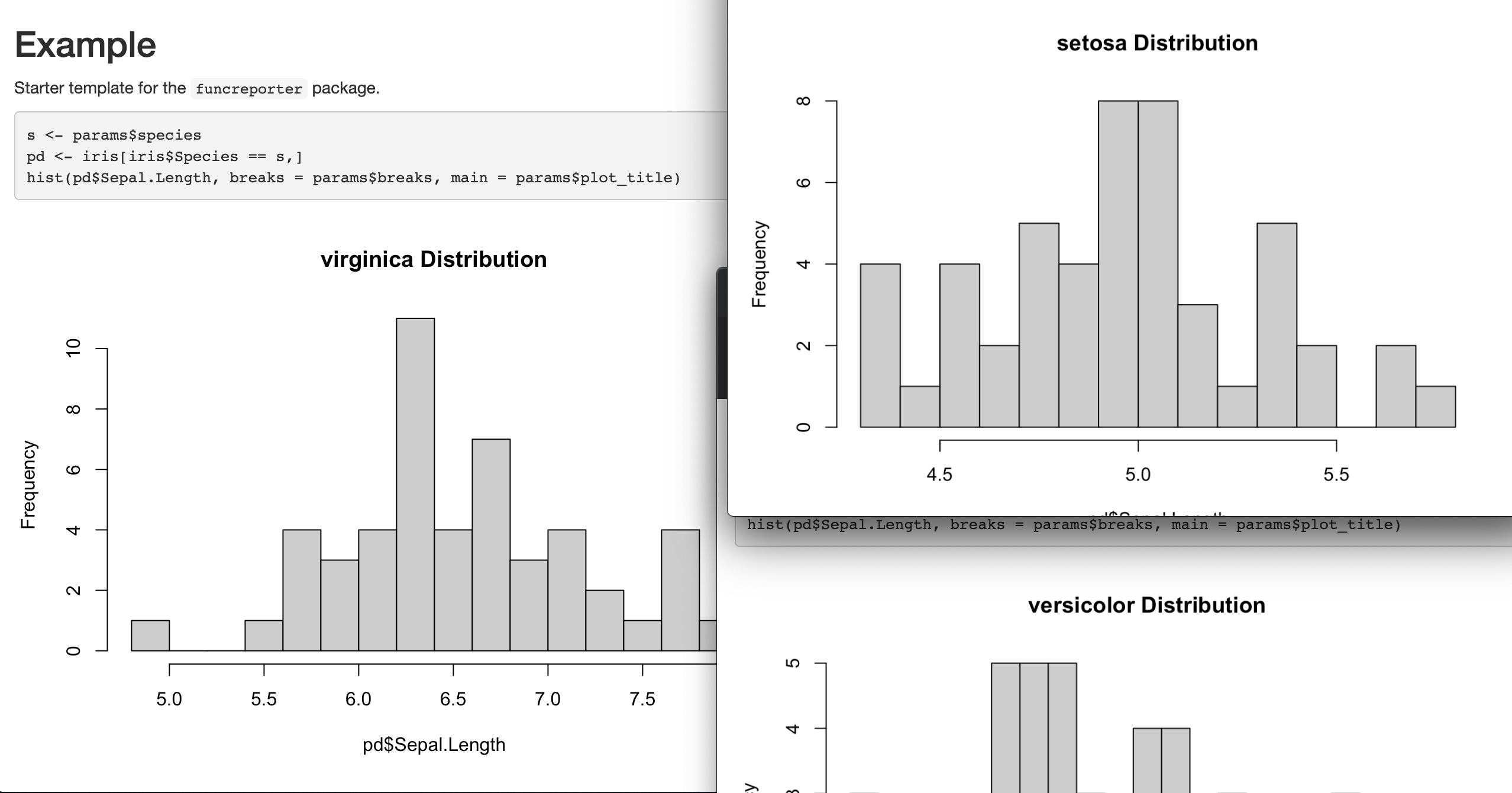
There’s been some recent commotion about automating Rmarkdown reports. And surprisingly, there isn’t (yet) an RStudio-sanctioned method of doing so. We’ve been left to our own devices, at least for the moment.
[Read More]
'Looping' and 'Branching' with Pipes
Whilst programming, I am a Don’t Repeat Yourself (DRY) devotee. I am also frequently side-tracked by ancillary exploration: “Hmmm, what about this instead?” “What if I tried this really quick?” “Ohhhh should I check this variable too?” My point is this: exploratory data analysis is seldom linear; I often want...
[Read More]
Building Complex SQL Queries with R
The {dbplyr} package is a godsend for tidyverse devotees. While SQL has its own elegance and expressiveness, once you go tbl() %>% ... %>% collect(), you can never go back. Ah, but I must immediately hedge: there are admittedly some tasks whose complexity requires a more…intimate interaction with the database....
[Read More]
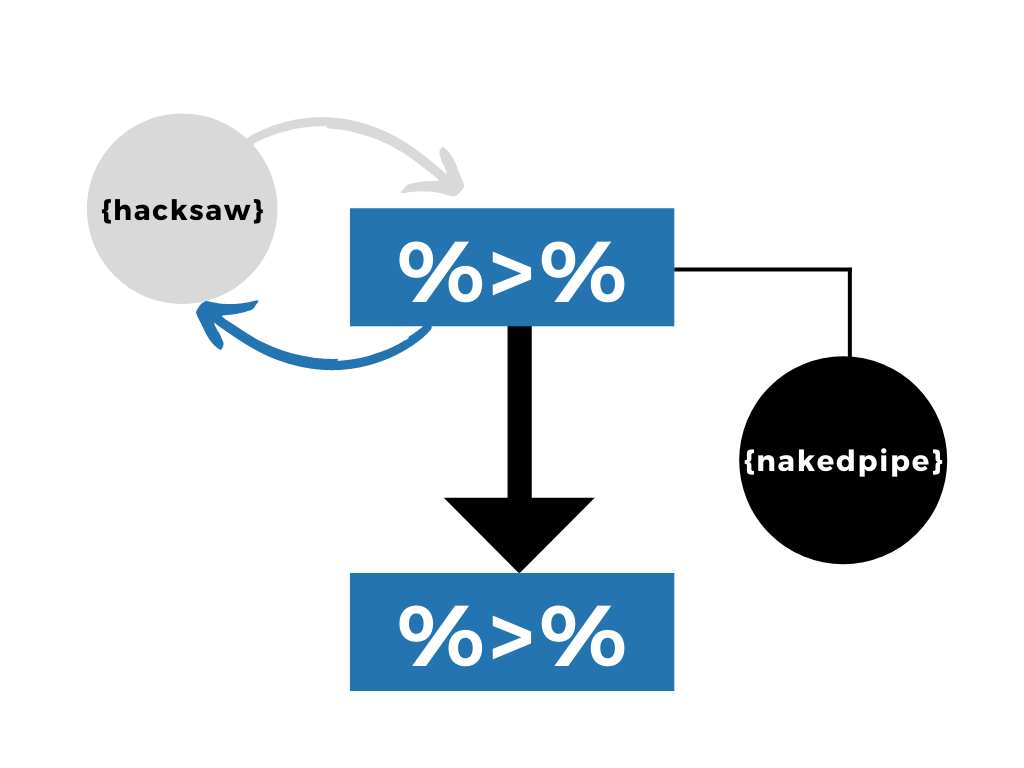
Introducing the hacksaw package
Moving between dplyr and purrr is usually a delight. There are, however, some exceptions that led to the creation of {hacksaw}, my new package for extra tidyverse-like functionality. Splitting and mapping over data frames has never been easier.
[Read More]
Who's the best player to sign in the Premier League?
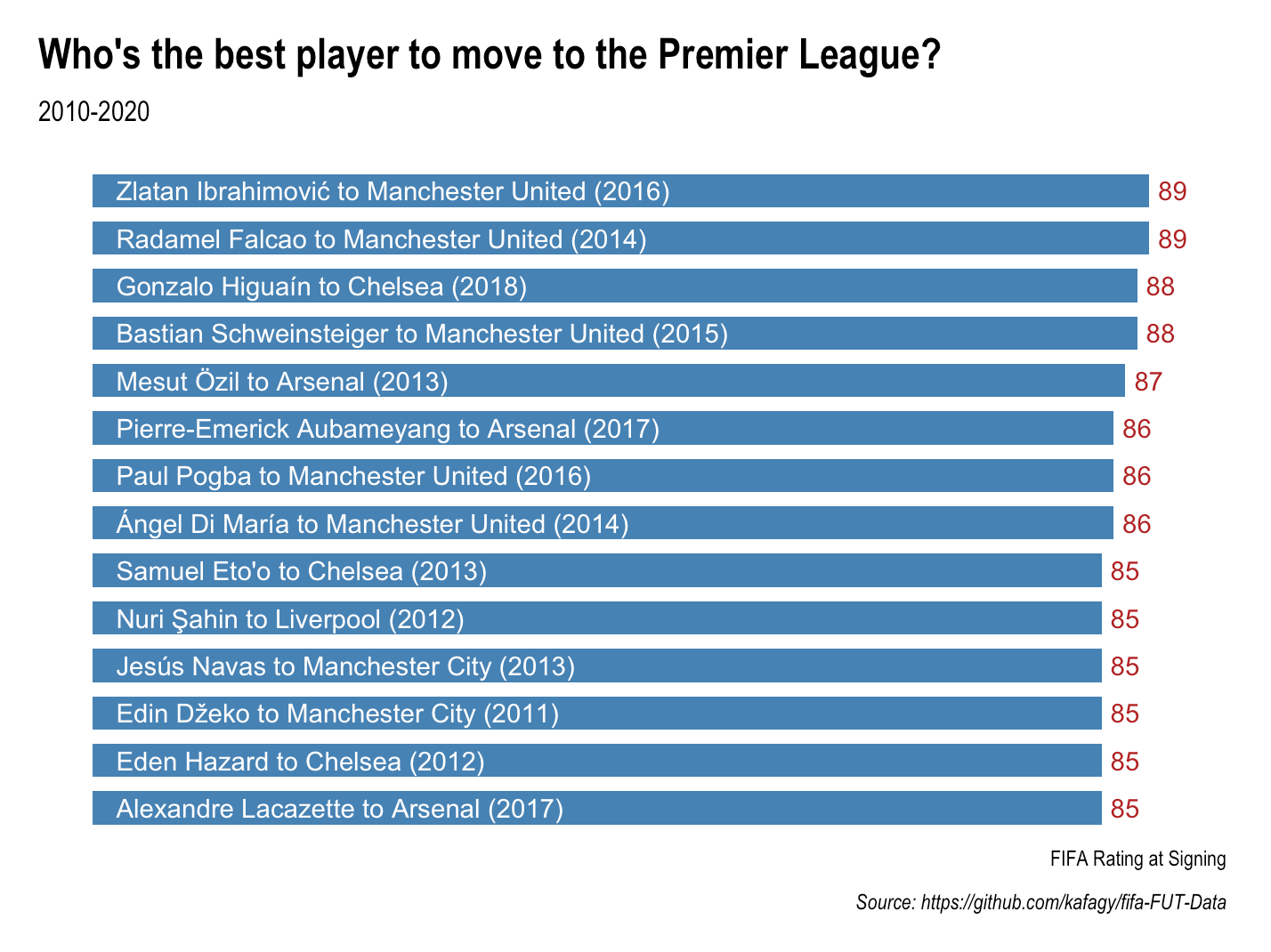
The purpose of this post is threefold: (1) to answer the question, “Who’s the best player that’s moved to the Premier League, at the time of signing?”;1 (2) to convince Ryan O’Hanlon to abandon Google Sheets in favor of R; and (3) to dismay fellow United fans everywhere. This excludes...
[Read More]